MybatisPlus知识查漏补缺
简介
MyBatis-Plus 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生
特性
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
框架结构
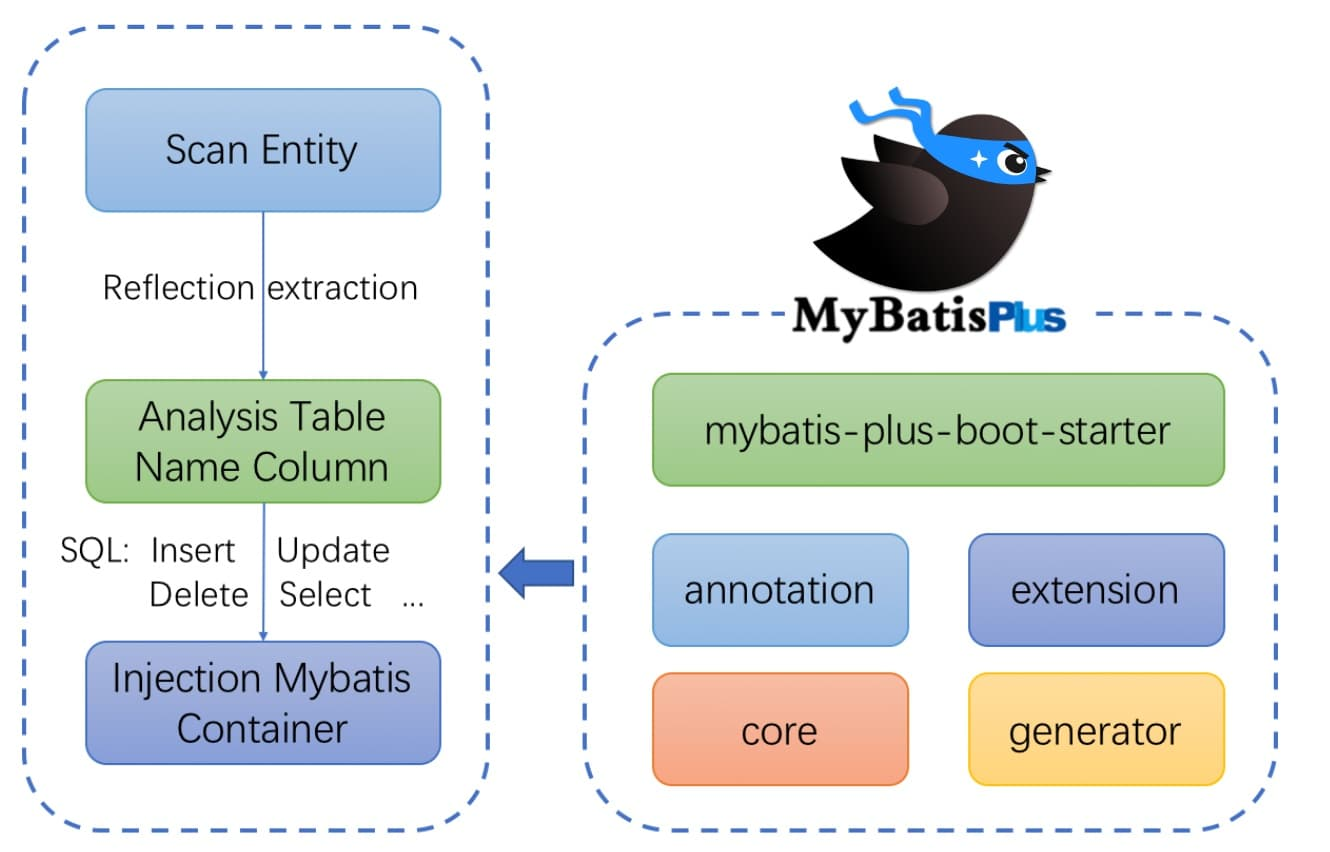
环境搭建
记录Spring+MybatisPlus环境的搭建(完全注解)
添加Spring配置核心类
1 | |
添加Mybatis配置核心类
1 | |
测试
1 | |
常用注解
-
@TableName:指定类所表示的表名
-
TableId:标明主键
-
value:若属性名与数据库字段名称不一致,可以使用此属性
-
type:主键生成策略
主键生成策略 描述 IdType.ASSIGN_ID(默认) 基于雪花算法的策略生成数据id,与数据库id是否设置自增无关 IdType.AUTO 使用数据库的自增策略,注意,该类型请确保数据库设置了id自增
-
-
@TbaleField:指定属性所表示的字段名
-
@TableLogic:指定逻辑删除标识符
条件构造器
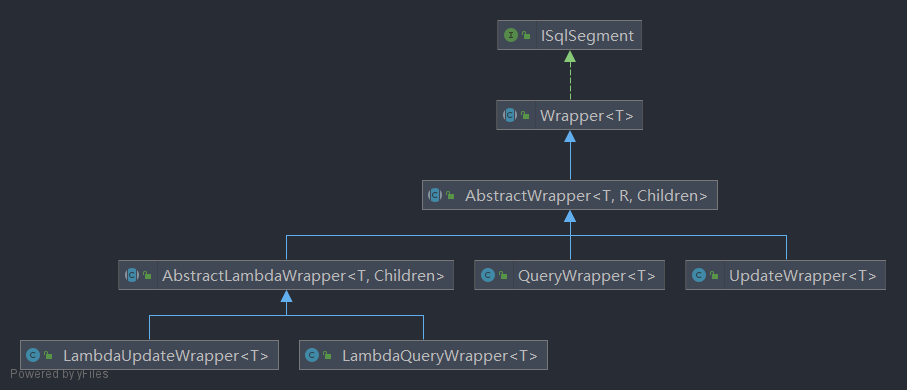
Wrapper: 条件构造抽象类,最顶端父类AbstractWrapper: 用于查询条件封装,生成 sql 的 where 条件QueryWrapper: 查询条件封装UpdateWrapper: Update 条件封装AbstractLambdaWrapper: 使用Lambda 语法LambdaQueryWrapper:用于Lambda语法使用的查询WrapperLambdaUpdateWrapper: Lambda 更新封装Wrapper
QueryWrapper
组装查询排序条件
1 | |
条件的优先级
1 | |
组装select子句
1 | |
实现子查询
1 | |
UpdateWrapper
1 | |
UpdateWrapper不仅拥有QueryWrapper的组装条件功能,还提供了set方法进行修改对应条件的数据库信息
condition
1 | |
先判断用户是否选择了这些条件,若选择则需要组装该条件,若没有选择则一定不能组装,以免影响SQL执行的结果
LambdaQueryWrapper
1 | |
功能等同于QueryWrapper,提供了Lambda表达式的语法可以避免填错列名
LambdaUpdateWrapper
1 | |
功能等同于UpdateWrapper,提供了Lambda表达式的语法可以避免填错列名
常用插件
分页插件
mybatis-plus自带分页插件
使用方式
在配置类中添加
1 | |
使用
1 | |
自定义方法启用分页
mapper和mapper.xml中分别添加查询方法
1 | |
使用
1 | |
乐观锁和悲观锁
乐观锁
乐观锁总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(具体方法可以使用版本号机制或 CAS 算法);
乐观锁通常多于写比较少的情况下(多读场景),避免频繁加锁影响性能,大大提升了系统的吞吐量;
Java中的java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式 CAS 实现的;
mybatis-plus的乐观锁实现方式:
- 取出记录时,获取当前 version
- 更新时,带上这个 version
- 执行更新时, set version = newVersion where version = oldVersion
- 如果 version 不对,就更新失败
悲观锁
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放;
即共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程;
Java 中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现;
开启乐观锁插件
实体类添加@Version注解
1 | |
添加乐观锁插件配置
1 | |
通用枚举
-
创建枚举类
-
方式一:使用
@EnumValue标记需要存储到数据库的属性1
2
3
4
5
6
7
8
9
10
11
12
13
14
15@Getter
public enum UserSex {
FEMALE(0, "女"),
MALE(1, "男");
// 将注解所标识的属性的值存储到数据库中
@EnumValue
private final Integer value;
private final String name;
UserSex(Integer value, String name) {
this.value = value;
this.name = name;
}
} -
方式二:实现
IEnum<T>接口,getValue()方法标记存储到数据库的值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18@Getter
public enum UserSex2 implements IEnum<Integer> {
FEMALE(0, "女"),
MALE(1, "男");
private final Integer value;
private final String name;
UserSex2(Integer value, String name) {
this.value = value;
this.name = name;
}
@Override
public Integer getValue() {
return this.value;
}
}
-
-
实体类属性使用枚举类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21@Getter
@Setter
@TableName("t_user")
public class TUser {
@TableId
private Integer id;
private String name;
private UserSex sex;
private String password;
private Integer age;
private String email;
@TableLogic
private Integer isDeleted;
} -
配置全局默认枚举类型处理器
1
2
3
4
5
6// ...
MybatisConfiguration configuration = new MybatisConfiguration();
// 配置全局默认枚举类型处理器
configuration.setDefaultEnumTypeHandler(MybatisEnumTypeHandler.class);
sessionFactoryBean.setConfiguration(configuration);
// ...
多数据源
适用场景:纯粹多库、 读写分离、 一主多从、 混合模式等
下面以spring-boot项目作为配置示例
引入依赖
1 | |
编写配置文件
1 | |
在Service上指定操作的数据源
1 | |
字段类型处理器
类型处理器,用于 JavaType 与 JdbcType 之间的转换,用于 PreparedStatement 设置参数值和从 ResultSet 或 CallableStatement 中取出一个值
1 | |
自动填充功能
原理:
-
实现元对象处理器接口:com.baomidou.mybatisplus.core.handlers.MetaObjectHandler
-
注解填充字段
@TableField(fill = FieldFill.INSERT)生成器策略部分也可以配置1
2
3
4
5
6public class User {
// 注意!这里需要标记为填充字段
@TableField(fill = FieldFill.INSERT)
private String fillField;
}
-
自定义实现类 MyMetaObjectHandler
1
2
3
4
5
6
7
8
9
10
11
12
13@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
this.strictInsertFill(metaObject, "createTime", () -> LocalDateTime.now(), LocalDateTime.class);
}
@Override
public void updateFill(MetaObject metaObject) {
this.strictUpdateFill(metaObject, "updateTime", () -> LocalDateTime.now(), LocalDateTime.class);
}
}
拓展知识
雪花算法
背景
需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。 数据库的扩展方式主要包括:业务分库、主从复制,数据库分表。
数据库分表
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务 继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。例如,淘宝的几亿用户数据, 如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,此时就需要对单表数据进 行拆分。 单表数据拆分有两种方式:垂直分表和水平分表
-
垂直分表:垂直分表适合将表中某些不常用且占了大量空间的列拆分出去
-
水平分表:水平分表适合表行数特别大的表;水平分表相比垂直分表,会引入更多的复杂性,例如要求全局唯一的数据id该如何处理
-
主键自增:以最常见的用户 ID 为例,可以按照 1000000 的范围大小进行分段,1 ~ 999999 放到表 1中, 1000000 ~ 1999999 放到表2中,以此类推
- 复杂点:分段大小的选取,需要根据业务选取合适 的分段大小
- 优点:可以随着数据的增加平滑地扩充新的表;如,现在的用户是 100 万,如果增加到 1000 万, 只需要增加新的表就可以了,原有的数据不需要动
- 缺点:分布不均匀
-
取模:同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,可以简单地用 user_id % 10 的值来 表示数据所属的数据库表编号,ID 为 985 的用户放到编号为 5 的子表中,ID 为 10086 的用户放到编号 为 6 的子表中
- 复杂点:初始表数量的确定;表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题
- 优点:表分布比较均匀
- 缺点:扩充新的表很麻烦,所有数据都要重分布
-
雪花算法:它能够保证不同表的主键的不重复性,以及相同表的 主键的有序性
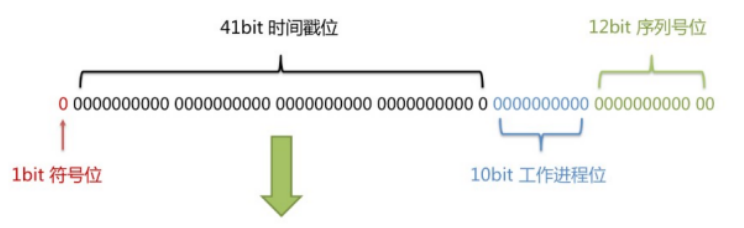
- 长度共64bit(一个long型)
- 符号位,1bit
- 时间戳位,41bit,毫秒级,存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于69.73年
- 机器ID(5bit是数据中心,5bit是机器ID),10bit,可以部署在1024个节点
- 流水号,12bit号(意味着每个节点在每毫秒可以产生 4096 个 ID)
- 优点:整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高
- 长度共64bit(一个long型)
-