JAVA基础知识回顾及查漏补缺
Java标准版=Java SE=J2SE(提供了完整的Java核心API)
Java企业版=Java EE=J2EE(该技术体系中包含如Servlet、Jsp等,主要针对Web应用程序开发)
Java小型版=Java ME=J2ME(支持Java程序运行在移动终端,对Java API有所精简,Android出来后就没什么人用了)
Java的重要特点
- 是面向对象的:OOP
- 是健壮的:强类型机制、异常处理、垃圾回收等
- 是跨平台的:一次编译,到处运行(前提是平台上有JVM)
- 是解释型的:编译后的代码,不能直接被机器执行,需要有解释器来执行
Java的运行机制
JVM
核心机制:Java虚拟机(JVM)
- JVM是一个虚拟的计算机,具有指令集并使用不同的存储区域,负责执行指令,管理数据、内存、寄存器。包含在JDK中。
- JVM屏蔽了底层运行平台的差别,实现了“一次编译,到处运行”
JDK
- 全称为Java开发工具包,JDK=JRE+Java的开发工具(java、javac、javadoc、javap等工具)
- JRE(Java runtime environment)Java运行环境,JRE=JVM+JavaSE(Java核心类库)
- 想要运行一个开发号的Java程序,计算机中只需要安装JRE即可
- JDK提供给开发人员使用,其中包含Java的开发工具,也包含了JRE
运行机制
使用javac工具将编写的.java文件编译为.class文件(字节码文件),JVM执行.class文件,输出结果
数据类型
1字节=8bit
基本数据类型
数值型
数值型包括整型和浮点类型,浮点数=符号位+指数位+尾数位
小数的相等判断:以两个数差值的绝对值在某个精度范围内为相等依据
- byte:1字节,-128~127
- short:2字节,-215~215-1
- int:4字节,-231~231-1
- long:8字节,-263~263-1
- float:4字节,-3.40E38 ~ 3.40E38
- 除十进制表示外,还可用科学计数法表示,如 5.12e2=5.12*102、5.12e-2=5.12/102
- double:8字节,-1.79E308 ~ 1.79E308,浮点数默认为double,后加f或F声明为float类型
字符型
- char:2字节,存放单个字符,本质是一个整数,是unicode码对应的字符(&#数字;)
- ASCII:1字节,可以表示256个字符,但只用了128个
- Unicode:2字节,字母和汉字都是用2字节表示
- utf-8:大小可变的编码,字母使用1字节,汉字使用3字节
- gbk:可以表示汉字,范围广但小于utf-8,字母使用1字节,汉字使用2字节
- gb2312:可以表示汉字,范围小于gbk
- big5:繁体中文
布尔型
- boolean:1字节
基本类型精度顺序
- char > int > long > float > double
- byte > short > int > long > float > double
自动类型转换细节
-
容量(精度)小的类型可以自动转换为容量大的类型
-
(byte、short)和char之间不会互相自动转换
-
自动提升原则:多种类型的数据混合运算时,系统自动将所有数据转换为容量最大的那种数据类型,然后在进行计算
-
byte、short、char三种类型可以混合运算(单类型或多类型),在计算时会先转换为int
-
boolean不参与类型自动转换
强制类型转换细节
- 可能会造成精度损失或数据溢出
- 强转符号只针对于最近的操作数有效,使用小括号提升优先级
- byte和short类型在进行运算时,当做int类型处理
基本数据类型与String类型转换
- 基本数据类型转String类型:基本类型的值 + “” 即可
- String转基本数据类型:通过基本类型的包装类调用
parseXXX方法即可
引用数据类型
类
接口
数组
进制
1 | |
数据结构
类变量和类方法
对象分配机制
- 类信息(类的属性信息、方法信息)会加载到
方法区 - 在
堆中分配空间(地址)存放对象,对象中的字符串属性会存放到方法区的常量池中 - 对象名(对象引用)存放到
栈中,它的值是一个地址,地址指向堆中的对象

方法调用机制
- 当程序执行到方法时,会开辟一个独立的栈空间
方法传参机制
- 基本数据类型传递的是值,形参的改变不会影响实参
- 引用类型传递的是地址(其实也是值,只是值为地址),形参改变会影响实参(形参地址的改变不会影响实参)
方法可变参数
- 可变参数的实参可以为0个或任意多个
- 可变参数的实参可以为数组
- 可变参数的本质就是数组
- 可变参数可以和普通类型的参数一起放在形参列表,但必须保证可变参数在最后
- 一个形参列表中只能出现一个可变参数
变量作用域
- 属性和局部变量可以重名,访问时遵循就近原则
- 在同一个作用域中,两个局部变量不能重名
- 属性生命周期较长,与对象的创建和销毁同步。局部变量生】】命周期较短,伴随着它的代码块的执行而创建,伴随着代码块的结束而死亡,即在一次方法调用过程中
- 全局变量可以被本类使用,也可以被其他类通过对象调用来使用;局部变量只能在本类中对应的方法中使用
- 全局变量可以加修饰符;局部变量不可以加修饰符
构造方法
- 构造方法可以重载
- 构造方法与类名相同
- 构造方法无返回值
- 构造方法是完成对象的初始化,并不是创建对象
- 在创建对象时,系统自动调用该类的构造方法
- 若没有定义构造方法,系统编译时会自动给类生成一个无参构造
- 若定义了构造方法,系统就不会再自动生成一个无参构造,需要自己在代码中定义
对象创建流程
- 加载类信息,只会加载一次
- 在堆中分配空间(地址)
- 完成对象初始化
- 默认初始化:属性赋值对应类型的默认值(如int默认是0,String默认是null)
- 显式初始化:属性显式的赋值(如 int age = 100;)
- 构造方法初始化
- 把对象在堆中的地址返回给对象名(对象引用)
访问修饰符
- 公开级别:用
public修饰,对外公开 - 受保护级别:用
protected修饰,对子类或同一个包中的类公开 - 默认级别:没有修饰符,对同一个包中的类公开
- 私有级别:用
private修饰,只有类本身可以访问,不对外公开
面向对象
面向对象编程三大特征:封装、继承和多态
封装
封装就是把抽象出的数据(属性)和对数据的操作(方法)封装在一起,数据被保护在内部,程序的其他部分只有通过被授权的操作(方法),才能对数据进行操作。
封装的优点
- 隐藏实现细节
- 可以对数据进行验证,保证安全合理
继承
继承可以解决代码复用。当多个类存在相同的属性和方法时,可以从这些类中抽象出父类,在父类中定义这些相同的属性和方法,所有的子类不需要重新定义这些属性和方法,只需要通过extends来声明继承父类即可。
继承的优点
- 代码的复用性提高了
- 代码的扩展性和维护性提高了
继承的细节
- 子类继承了所有的属性和方法,非私有的属性和方法可以在子类直接访问,但是私有属性和方法不能在子类直接访问,要通过公共的方法去访问
- 子类必须调用父类的构造器,完成父类的初始化(编译器会自动生成)
- 当创建子类对象时,不管使用子类的哪个构造器,默认情况下总会去调用父类的无参构造器,如果父类没有提供无参构造器,则必须在子类的构造器中用
super去指定使用父类的哪个构造器完成父类的初始化工作,否则,编译不通过 - 若希望指定去调用父类的某个构造器,则显示的调用一下
super在使用时,需要放在构造器第一行(super只能在构造器中使用)super和this都只能放在构造器第一行,因此这两个方法不能共存在一个构造器- 所有类都是Object类的子类
- 父类构造器的调用不限于直接父类,一直往上追溯知道Object类
- 子类最多只能继承一个父类(直接继承)
- 不能滥用继承,子类和父类之间必须满足 is-a 的逻辑关系
子类创建的内存布局
示例代码:
1 | |
上面代码的内存布局如下:

子类创建过程
- 按子类的继承关系从上到下,将类加载到方法区
- 在堆中分配子类对象的空间
- 按子类的继承关系从上到下,初始化各类的属性
- 子类对象名指向对象地址
子类对象属性查询规则
- 按继承关系从下向上查找第一个可以被访问的该属性,并返回
多态
多态:方法或对对象具有多种形态,多态是建立在封装和继承基础之上的
多态的具体体现
- 方法的多态:重写和重载
- 对象的多态
- 一个对象的编译类型(父类)和运行类型(子类)可以不一致
- 编译类型在定义对象时就确定了,不能改变
- 运行类型是可以变化的
- 编译类型:定义时 = 号的左边,运行类型:= 号的右边
多态的注意事项及细节
- 多态的前提是:两个对象(类)存在继承关系
- 多态的向上转型
- 本质:父类的引用指向了子类的对象
- 语法:父类类型 引用名 = new 子类类型();
- 特点:编译类型看左边,运行类型看右边;可以调用父类中的所有成员(需遵守访问权限),不能调用子类中特有成员,最终运行效果看子类的具体实现
- 多态的向下转型
- 语法:子类类型 引用名 = (子类类型) 父类引用;
- 只能强转父类的引用,不能强转父类的对象
- 要求父类的引用必须指向的是当前目标类型的对象(编译类型和运行类型都为子类类型)
- 当向下转型后,可以调用子类类型中的所有成员
- 属性没有重写之说,属性的值看编译类型(比如父类和子类相同属性默认值不同时,父类 引用名 = 子类,引用名.属性 = 父类的默认值,即动态绑定机制)
- instanceOf 用于判断对象的类型是否为XX类型或XX类型的子类型
动态绑定机制
- 当调用对象方法时,该方法会和该对象的内存地址(运行类型)绑定
- 当调用对象属性时,没有动态绑定机制,哪里声明,哪里使用(编译类型)
static关键字
类变量
- 类中用static关键字修饰的变量称为类变量(静态变量)
- 类的类变量是所有对象实例共享的,所有的访问和修改都是同一个变量
- Java7之前,类变量存放在方法区,之后,存放在堆中
- 类变量在类加载时就被分配空间
类方法
类中用static关键字修饰的方法称为类方法(静态方法)
经典使用场景
- 当方法中不涉及到任何和对象相关的成员,则可以将方法设计为静态方法,提高发开效率
- 工具类
使用注意事项和细节
- 类方法和普通方法都是随着类的加载而加载,将结构信息存储在方法区,类方法中无this的参数
- 类方法可以通过类名调用,也可以通过对象名调用
- 普通方法和对象相关,需要通过对象名调用,不能通过类名调用
- 类方法中不允许使用和对象有关的关键字,比如this和super
- 类方法中只能访问类变量或类方法
- 普通成员方法既可以访问普通变量和方法,也可以方法类变量和方法
理解main方法
- main方法由jvm调用,所以该方法的访问权限必须是public
- jvm在执行main方法时不必创建对象,所以该方法必须是static
- 在main方法中,可以直接调用该main方法所在类的类变量和类方法
代码块
基本介绍
-
代码块又称为初始化块,属于类成员,类似于方法,可以将逻辑语句封装在方法体内,通过
{}包围起来 -
和方法不同,没有方法名,没有返回,没有参数,只有方法体,不能通过对象或类名显式调用,而是在类加载时,或创建对象时隐式调用
-
代码块在构造器之前执行
-
语法如下(加修饰符的话,只能加static)
1
2
3[static]{
};
使用注意事项和细节
- 静态代码块,作用就是对类进行初始化,它随着类的加载而执行,并且只会执行一次。普通代码块,每创建一个对象就执行
- 类什么时候被加载
- 创建对象实例时(new)
- 创建子类对象实例,父类也会被加载
- 使用类的静态成员时(静态属性,静态方法)
- 如果只使用类的静态成员,普通代码块并不会执行
- 创建一个对象时,在一个类调用顺序是:
- 调用静态代码块和静态属性初始化(优先级一致,按定义的顺序调用)
- 调用普通代码块和普通属性的初始化(优先级一致,按定义顺序调用)
- 调用构造方法
- 构造方法的最前面其实隐含了super()和调用普通代码块
- 创建一个子类时的调用顺序
- 父类静态代码块和静态属性初始化
- 子类静态代码块和静态属性初始化
- 父类普通代码块和普通属性初始化
- 父类构造方法
- 普通代码块和普通属性初始化
- 子类构造方法
- 静态代码块只能调用类变量和类方法
final关键字
final关键字可以修饰类、属性、方法和局部变量
使用场景
- 当不希望类被继承时
- 当不希望父类的某个方法被子类覆盖/重写时
- 当不希望类的某个属性的值被修改时
- 当不希望某个局部变量被修改时
使用注意事项和细节
- final修饰的属性在定义时,必须赋初始值,并且以后不能再修改
- 定义时(等号右侧赋值)
- 构造器中赋值
- 代码块中赋值
- 若final修饰的属性是静态的,则初始化的位置只能是定义时和静态代码块
- final类不能被继承,但是可以实例化对象
- 若类不是final类,但含有final方法,则该方法虽不能重写,但是可以被继承
- 一般来说,若一个类已经是final类了,就没有必要再将方法修饰成final方法
- final不能修饰构造方法
- final和static往往搭配使用,不会导致类加载,效率更高,底层编译器做了优化处理
- 包装类、String也是final类
抽象类
使用注意事项和细节
- 用abstract关键字修饰一个类时,该类就是抽象类
- 用abstract关键字修饰一个方法时,该方法就是抽象方法
- 抽象类的价值更多作用是在于设计,是设计者设计好后,让子类继承并实现抽象类
- 抽象类可以有任意成员
- 抽象方法不能有方法主体
- 若一个类继承了抽象类,则它必须实现抽象类的所有抽象方法,除非它自己也声明为抽象类
接口
接口就是给出一些没有实现的方法,封装到一起,到某一个类要使用的时候,在根据具体情况把这些方法写出来。
jdk8之后接口可以有默认实现方法(需要使用default关键字修饰)、静态方法(用static关键字修饰)。
使用注意事项和细节
- 接口不能被实例化
- 接口中所有的方法是public方法,接口中抽象方法可以不用abstract关键字修饰
- 一个普通类实现接口,就必须将该接口的所有方法都实现
- 抽象类实现接口,可以不用实现接口的方法
- 一个类同时可以实现多个接口
- 接口中的属性只能是final,而且是 public static final 修饰符(如接口中定义 int num=1; 实际上是 public static final int num=1;)
- 接口中属性的访问形式:接口名.属性名
- 一个接口不能继承其他的类,但是可以继承多个别的接口
- 接口的修饰符只能是public和默认
接口与继承类
- 继承的价值主要在于:解决代码的复用性和可维护性
- 接口的价值主要在于:设计好各种规范,让其他类去实现这些方法
- 接口比继承更加灵活,继承是满足is-a的关系,接口只需满足like-a的关系
- 接口在一定程度上实现代码解耦
接口的多态性
- 多态参数,接口引用可以指向实现了接口的类的对象
- 多态数组
- 接口存在多态传递现象(接口未实现的方法会向下传递直至实现)
内部类
一个类的内部又完整的嵌套了另一个类结构,是类的五大成员之一(属性、方法、构造器、代码块、内部类)。内部类最大的特点就是可以直接访问私有熟悉,并且可以体现类与类之间的包含关系。
局部内部类
定义在外部类的局部位置,通常在方法中。
- 可以直接访问外部类的所有成员
- 不能添加访问修饰符,因为它的地位就是一个局部变量,可以使用final修饰
- 作用域:仅定义它的方法或代码块中
- 若外部类和局部内部类的成员重名时,默认遵循就近原则,若想访问外部类的成员,则可以使用 外部类名.this.成员 去访问(外部类.this的本质就是外部类的对象,即哪个对象调用了内部类所在方法,外部类.this就是哪个对象)
匿名内部类
定义在外部类的局部外置,比如方法中,并且没有类名,同时还是一个对象。
- 基本语法:new 类或接口(参数列表){ 类体 };
- 使用匿名内部类可以简化开发
- 编译类型为new后面的类或接口,运行类型为匿名内部类,底层在运行时会给这个匿名内部类分配一个名字(外部类名+$数字)
- jdk底层在创建匿名内部类后,立即就创建了匿名内部类的实例,并把地址返回给引用名
- 匿名内部类使用一次就不能再使用
使用注意事项和细节
-
匿名内部类既是一个类的定义,同时它本身也是一个对象
1
2
3
4
5
6
7
8
9
10
11
12new Dog(){
@Override
public void eat() {
}
}.eat();
Dog d = new Dog(){
@Override
public void eat() {
}
};
d.eat(); -
可以直接访问外部类的所有成员
-
不能添加访问修饰符,因为它的地位就是一个局部变量
-
作用域:仅定义它的方法或代码块中
-
外部类不能访问匿名内部类的成员
-
若外部类和匿名内部类的成员重名时,访问规则同局部内部类
最佳实践
- 当做实参直接传递,简洁高效
成员内部类
成员内部类是定义在外部类的成员位置,并且没有static修饰
- 可以直接访问外部类的所有成员
- 可以添加任意访问修饰符,它的地位就是一个成员
- 作用域:和外部类的其他成员一样,为整个类体
- 外部类通过创建内部类对象,再访问
- 其他外部类通过外部类实例.new 内部类(outer.new Inner())创建内部类对象,或者通过外部类实例调用方法获取内部类实例,再访问
- 若外部类和成员内部类的成员重名时,访问规则同局部内部类
静态内部类
成员内部类是定义在外部类的成员位置,并且有static修饰
- 可以直接访问外部类的所有静态成员
- 可以添加任意访问修饰符,它的地位就是一个静态成员
- 作用域:和外部类的其他成员一样,为整个类体
- 外部类通过创建静态内部类对象,再访问
- 若外部类和静态内部类的成员重名时,默认遵循就近原则,若想访问外部类的成员,则可以使用 外部类名.成员 去访问
枚举和注解
枚举实现方式
- 自定义类实现枚举
- 构造器私有化
- 本类内部创建一组对象
- 不提供set方法,枚举对象通常为只读
- 对外暴露对象(通过为对象添加 public final static 修饰符)
- enum关键字实现枚举
enum关键字实现枚举注意事项
- 默认会继承Enum类,而且是一个final类(通过javap等反编译工具可以看到)
- 和普通类一样可以实现接口
- 若使用无参构造器创建枚举对象,则实参列表和小括号都可以省略
- 当有多个枚举对象时,使用
,间隔,左右有一个分号结尾 - 枚举对象必须放在枚举类的行首
注解
注解也被称为元数据,用于修饰解释包、类、方法、属性、构造器、局部变量等数据信息。
修饰注解的注解被称为元注解,如@Target
元注解
- @Retention:指定注解的作用范围,SOURCE、CLASS、RUNTIME
- SOURCE:编译器使用后,直接丢弃注解
- CLASS:编译器将把注解记录在class文件汇总,当运行Java程序时,JVM不会保留注解,是默认值
- RUNTIME:编译器将把注解记录在class文件中,当运行Java程序时,JVM会保留注解,程序可以通过反射获取该注解
- @Target:指定注解可以在哪些地方使用
- @Documented:指定该注解是否会在Javadoc体现
- @Inherited:子类会继承父类注解
异常
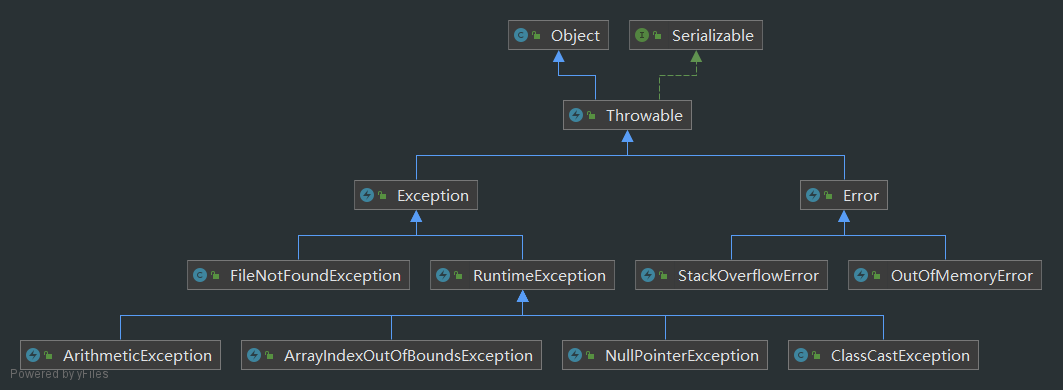
异常类型
Error
JVM无法解决的严重问题。如:JVM系统内部错误、资源耗尽等严重情况。如:StackOverflowError(栈溢出)和OOM(内存溢出),Error是严重错误,程序会崩溃
Exception
因编程错误或偶然的外在因素导致的一般性问题,可以使用针对性代码进行处理,如空指针异常、网路连接中断等。Exception分为两大类:运行时异常和编译时异常
异常体系图
异常处理
- try-catch-finally:捕获发生的异常,自行处理
- throws:将异常抛出,交给调用方来处理,最顶级的处理者为JVM(异常抛到JVM后,输出异常信息,退出程序)
throws和throw区别
- throws:异常处理的一种方式,声明在方法处,后面跟着异常类型
- thorw:手动抛出异常的关键字,声明在方法体中,后面跟着异常对象
常用类
包装类
包装类:针对8中基本数据类相应的引用类型,有了类的特点,可以调用类中的方法。
6中数字类型的包装类都是继承自Number类。
装箱
基本数据类型转为包装类,自动装箱本质是调用了包装类的valueOf方法
拆箱
包装类转为基本数据类型,自动拆箱本质是调用了包装类的xxxValue方法(xxx为对应基本数据类型名称)
其他注意事项
- Integer对象的比较
1 | |
- 同上面的原理,Short和Long对象的比较也是如此,且缓存范围也是-127~128
- 三元表达式有强转功能,返回值类型为两个返回值中类型精度更高的那个类型
String
基本概念
- String对象用于保存字符串,也就是一组字符序列(char数组)
- 字符串常量使用双引号括起来的字符序列
- 字符串的字符使用Unicode字符编码,一个字符(不区分字母还是汉字)占两个字节
- String是一个final类,不可被其他类继承,包含一个被final修饰的char数组属性(value)
创建方式
直接赋值
1 | |
底层逻辑:先从常量池查看是否有"abcd"数据空间。若有,则直接指向改空间;若无,则重新创建,然后指向。最终指向的是常量池的空间地址。
调用构造器
1 | |
底层逻辑:先在堆中创建空间,属性value指向常量池中"abcd"空间。若常量池中有"abcd",则value直接指向改空间;若无,则重新创建,在指向。对象最终指向的是堆中的空间地址。
使用注意事项和细节
-
字符串常量相加赋值给对象,编译器会优化为一个字符串常量赋值给对象,对象最终指向常量池中空间
1
String s = "abc" + "de"; // 编译器优化为 String s = "abcde"; -
字符串变量相加赋值给对象,本质为调用StringBuilder的append和toString方法,toString方法会执行new String,对象最终指向堆中空间
StringBuffer
基本概念
-
继承AbstractStringBuilder类,包含一个不被final修饰的char数组属性(value)
-
是一个final类,不可被继承
-
StringBuffer代表可变的字符序列,可以对字符串内容进行增删
-
是可变长度的
与String的区别
- String保存的是字符串常量,里面的值不能更改,每次变更实际就是更改地址,效率较低
- StringBuffer保存的是字符串变量,里面的值可以更改,每次变更实际就是更新内容,不用更改地址,效率较高
StringBuilder
基本概念
- 继承AbstractStringBuilder类,提供一个与StringBuffer兼容的API,但不保证同步(不是线程安全的)。一般在单线程中使用,建议优先采用该类,它比StringBuffer要快
- 是一个可变字符序列
日期类
- Date:第一代日期类
- Calendar:第二代日期类,Calendar类引入JDK后,Date的大部分方法被弃用
- LocalDate、LocalTime、LocalDateTime:第三代日期类,解决了前面两代存在的一些问题,如下
- 可变性:像日期和时间这样的类应该是不可变的
- 偏移性:Date中的年份是从1900年开始的,而月份是从0开始
- 格式化:格式化只对Date有用,Calendar则不行
- 不是线程安全的
- 不能处理闰秒(每隔2天,多出1s)
- Instant:时间戳类
集合
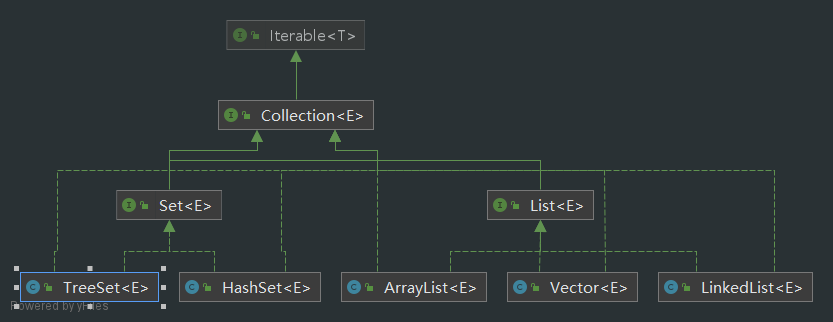
集合的框架体系图
单列集合
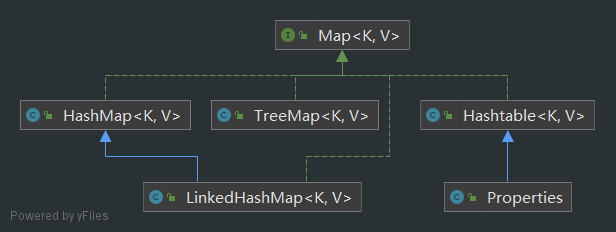
双列集合(键值对)
List接口
- List集合类中元素是有序的,且可以重复
- List集合类的每个元素都有其对应的顺序索引,可以根据索引存取容器中的元素
ArrayList
-
内部是由数组来实现数据存储
-
线程不安全
-
允许对元素进行快速随机访问
-
数组的缺点是每个元素之间不能有间隔,扩容时,将已有数组的数据复制到新的存储空间
-
插入删除操作时,需要对数组进行复制、移动,代价较高,适合随机查找和遍历,不适合插入和删除
-
扩容时,数组长度的增长率为当前数组长度的50%,即新长度=老长度*1.5
1
int newCapacity = oldCapacity + (oldCapacity >> 1);
Vertor
-
内部是由数组来实现数据存储
-
线程安全,所以效率比ArrayList慢
-
扩容时,数组长度的默认增长率为当前数组长度的100%,即新长度=老长度*2
1
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
LinkedList
- 内部是由双向链表存储数据
- 适合动态插入和删除,随机访问和遍历速度慢
- 可以当做堆栈、队列和双向队列使用
Set接口
- Set接口对象存放元素是无序的,元素不重复
- 元素取出的顺序虽然不是添加的顺序,但是是固定的
HashSet
- 内部由HashMap实现数据存储
- 去重机制:
- 通过
hashCode计算出hash值 - 通过hash值计算出索引
- 若在table数组索引位置没有数据,则直接加入
- 若存在数据,通过
equals方法比较,相同则不加入,不相同则不加入
- 通过
LinkedHashSet
- 是HashSet的子类
- 底层是一个LinkedHashMap,底层维护了一个数组+双向链表
- 使用链表维护元素的次序,使得元素看起来是以插入顺序保存的
TreeSet
-
内部由TreeMap实现数据存储
-
去重机制:
- 若调用无参构造器创建TreeSet对象,则使用添加对象实现的Comapreable接口的
compareTo方法进行比较,相同则不加入,不相同则加入;所以当添加对象及其父类没有实现Comapreable接口的话,程序运行会报错 - 若传入Comparator匿名对象到构造器来创建TreeSet对象,则使用Comparator匿名对象的
compare方法进行比较,相同则不加入,不相同则加入
1
2
3
4final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2)
: comparator.compare((K)k1, (K)k2);
} - 若调用无参构造器创建TreeSet对象,则使用添加对象实现的Comapreable接口的
-
使用无参构造器创建对象时,元素仍然是无序的
-
使用一个比较器来创建对象时,元素按顺序插入,若比较后相等,则元素不会插入
Map接口
- 用于保存具有映射关系的数据
- key和value可以是任何引用类型的数据
- key值不允许重复,value可以重复
- key和value可以为null,key为null时只能有一个
HashMap
-
底层是数组+链表+红黑树,当数组和链表达到一定长度,链表会转化为红黑树
1
2
3
4
5
6
7
8transient Node<K,V>[] table; // 数组
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; // 单向链表
} -
元素添加过程
- 取得hash值,计算为索引值
- 在table数组中查找索引位置是否有元素
- 若无元素,直接加入
- 若有元素,调用equals比较,若相同则放弃添加,若不同,则添加到该元素尾部
- 当一条链表的元素个数大于等于
TREEIFY_THRESHOLD(默认为8),且table数组大小大于等于MIN_TREEIFY_CAPACITY(默认为64)时,转化为红黑树
-
添加过程源码分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// hash算法,算法的主要目的是让所有元素能够均匀分布在数组上
// hashCode不等于hash值,hash值是由hashCode经过异或和位移计算出来的
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; // 辅助变量
if ((tab = table) == null || (n = tab.length) == 0)
// table数组为空,初始化数组长度为16
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
// (n - 1) & hash 计算出索引值
// 数组在索引位置没有元素时,将元素放到数组索引位置
tab[i] = newNode(hash, key, value, null);
else {
// 数组在索引位置上有元素
Node<K,V> e; K k; // 辅助变量
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 原有元素与新元素hash值、元素值相等,认为元素相同,不需要添加
e = p;
else if (p instanceof TreeNode)
// 原有元素为红黑树节点,将新元素挂到树上
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
// 遍历到链表尾部
if ((e = p.next) == null) {
// 将新元素挂到原有元素尾部
p.next = newNode(hash, key, value, null);
// 判断是否满足转化为红黑树条件
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 在遍历链表过程中,若发现元素相同,停止遍历
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
// 元素值覆盖
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} -
数组长度初始化后为16,当已使用长度大于总长度的0.75后,按原长度的
2倍进行扩容 -
不保证映射的顺序
-
线程不安全
Hashtable
- 存放的元素是键值对
- key和value都不能为null
- 底层是数组+链表,与HashMap区别是,新插入的元素在链表的头部
- 线程安全
- 数组长度初始化为11,当已使用长度大于总长度的0.75后,按原长度的
2倍+1进行扩容
Properties
- 是Hashtable的子类
- 可以从xxx.properties文件中,加载数据到Properties类对象,并进行读取和修改
- 通常作为配置文件对应类
TreeMap
- 底层是红黑树
- 使用无参构造器创建对象时,元素仍然无序
- 使用一个比较器来创建对象时,元素按顺序放入,若比较后相等,value替换原值
泛型
基本概念
- 泛型又称为参数化类型,解决数据类型的安全性问题
- 在类声明或实例化时只要指定好需要的具体的类型即可
- Java泛型可以保证如果程序在编译时没有发出警告,运行时就不会产生类型转换异常,使得代码更加简洁、健壮
- 泛型的作用:可以在类声明时通过一个标识标识类中某个属性的类型,或者是某个方法的返回值的类型,或者是参数类型
使用注意事项和细节
- 给泛型指定的数据类型只能是引用类型,不能是基本数据类型
- 在给泛型指定具体类型后,可以传入该类型或其子类型
自定义泛型
注意细节
- 普通成员可以使用泛型(属性、方法)
- 使用泛型的数组,不能初始化
- 静态方法中不能使用类的泛型(类加载时无法确定泛型类型)
- 泛型类的类型,是在创建对象时确定的
- 若在创建对象时,没有指定类型,默认为Object
自定义泛型接口
- 接口中,静态成员不能使用泛型
- 泛型接口的类型,在继承接口和实现接口时确定
- 没有指定类型,默认为Object
自定义泛型方法
- 泛型方法,可以定义在普通类中,也可以定义在泛型类中
- 当泛型方法被调用时,类型会确定
1 | |
泛型的继承和通配符
- 泛型不具备继承性
- <?>:支持任意泛型类型
- <? extends A>:上界通配符,支持A类以及A类的子类,规定了泛型的上限
- <? super A>:下界通配符,支持A类以及A类的父类,规定了泛型的下限
线程基础
基本概念
- 进程:是一个正在运行的程序
- 线程:线程由进程创建,一个进程可以有多个线程
- 单线程:同一时刻,只允许执行一个线程
- 多线程:同一时刻,可以执行多个线程
- 并发:同一时刻,多个任务交替执行,造成一种“貌似同时”的错觉,单核CPU实现的多任务就是并发
- 并行:同一时刻,多个任务同时执行,多核CPU可以实现并行
线程使用
创建线程的两种方式
- 继承Thread类,重写run方法
- 若调用run方法运行线程,并没有另起一个线程,依旧是调用方进程,方法调用处会阻塞
- 调用start方法运行线程,会启动一个新的线程
- 实现Runnable接口,重写run方法
- 直接调用run方法,并没有另起一个线程
- 使用时将对象传递给Thread类的构造器,来创建Thread对象,调用start运行
继承Thread和实现Runnable的区别
- 本质上没有区别,Thread也实现了Runnable接口
- 实现Runnable接口方式更加适合多个线程共享一个资源的情况,避免了单继承的限制
常用方法
-
start:start方法的本质是JVM底层调用该线程的start0方法
-
run:调用线程的run方法
-
getName/setName:设置线程名称
-
setPriority:设置线程优先级,范围1~10,越大优先级越高
-
sleep:线程休眠
-
interrupt:中断线程的休眠,不会终止线程
-
yield:线程的礼让;让出cpu,让其他线程执行,但礼让的时间不确定,所以不一定礼让成功
-
join:线程的插队;插队的线程一旦插队成功,则肯定先执行完插队线程的所有任务
用户线程和守护线程
- 用户线程:也叫工作线程,当线程的任务执行完或通知方式结束
- 守护线程:一般是为工作线程服务的,当所有的用户线程结束守护线程自动结束
- 常见的守护线程:垃圾回收机制
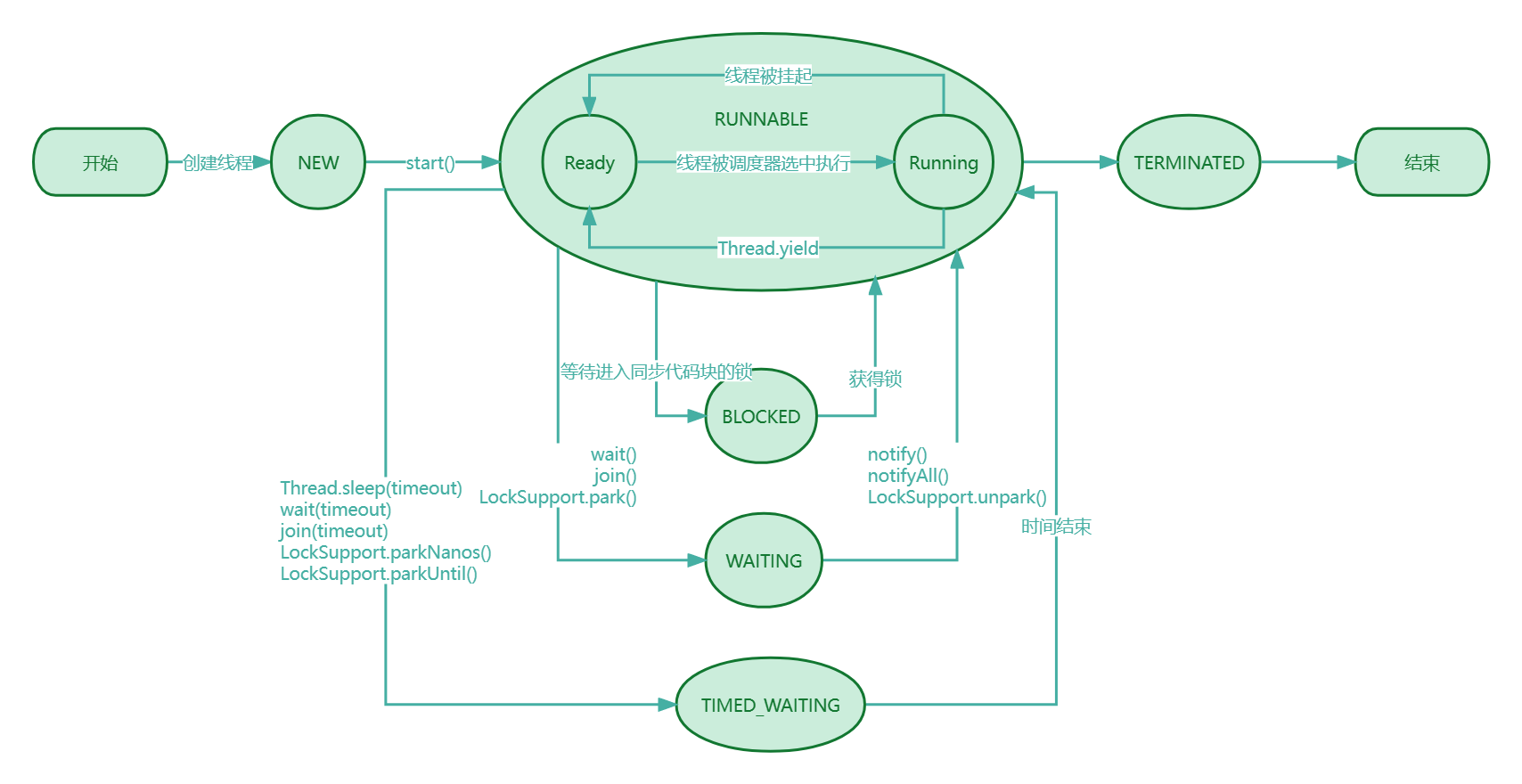
线程的生命周期
可以查看Thread.State枚举类
- NEW:尚未启动的线程处于此状态
- RUNNABLE:在Java虚拟机中执行的线程处于此状态
- BLOCKED:被阻塞等待监视器锁定的线程处于此状态
- WAITING:正在等待另一个线程执行特定动作的线程处于此状态
- TIMED_WAITING:正在等待另一个线程执行动作达到指定等待时间的线程处于此状态
- TERMINATED:已退出的线程处于此状态
Synchronized
线程同步机制
- 在多线程编程中,一些数据不允许被多个线程同时访问,此时使用同步访问技术,保证数据在任何时刻,最多只有一个线程访问,以保证数据的完整性
- 当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作,直到该线程完成操作,其他线程才能对该内存地址进行操作
同步使用方式
- 同步代码块
1 | |
- synchronized还可以放在方法声明中,表示整个方法为同步方法
互斥锁
- 对象互斥锁保证共享数据操作的完整性
- 每个对象都对应于一个可称为”互斥锁“的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象
- 使用关键字 synchronized 来与对象的互斥锁联系,当对象被 synchronized 修饰时,表明该对象在任一时刻只能由一个线程访问
- 同步的局限性:导致程序的执行效率要降低
- 非静态同步方法的锁可以是this,也可以是其他对象(要求是同一个对象)
- 静态同步方法的锁为当前类本身
释放锁的情况
- 当前线程的同步方法、同步代码块执行结束
- 当前线程在同步方法、同步代码块中遇到break、return
- 当前线程在同步方法、同步代码块中出现了未处理的异常
- 当前线程在同步方法、同步代码块中执行了线程对象的wait()方法,当前线程暂停,并释放锁
IO流
按操作数据单位不同分为:字节流(8bit),字符流(按字符,字符的长度和文件编码有关)
按数据流的流向不同分为:输入流,输出流
按流的角色的不同分为:节点流,处理流/包装流
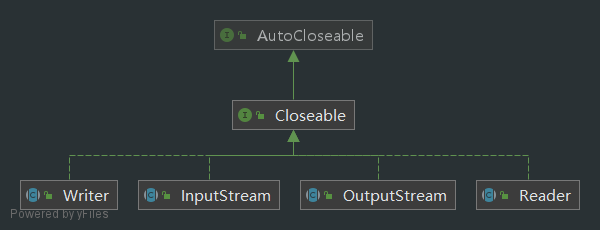
输入流
字节输入流、字符输入流
- InputStream:字节输入流
- FileInputStream:文件字节输入流
- BufferedInputStream:缓冲字节输入流
- ObjectInputStream:对象字节输入流,用于从文件反序列化恢复为对象
- Reader:字符输入流
- FileReader:文件字符输入流
- BufferedReader
- InputStreamReader:将InputStream(字节流)包装成Reader(字符流)
输出流
字节输出流、字符输出流
- OutputStream:字节输出流
- FileOutputStream:文件字节输出流
- BufferedOutputStream
- ObjectOutputStream:对象字节输出流,用于将对象序列化保存到文件
- Writer:字符输出流
- FileWriter
- BufferedWriter
- OutputStreamWriter:将OutputStream(字节流)包装成Writer(字符流)
节点流和处理流
节点流
节点流可以从一个特定的数据源读写数据,FileReader、FileWriter
处理流
处理流也叫包装流,是连接已存在的流(节点流或处理流)之上,为程序提供更为强大的读写功能,如BufferedReader、BufferedWriter
节点流和处理流的区别和联系
- 节点流是底层流/低级流,直接跟数据源相接
- 处理流包装节点流,既可以消除不同节点流的实现差异,也可以提供更方便的方法来完成输入输出
- 处理流对节点流进行包装,使用了修饰器设计模式,不会直接与数据源相连
- 处理流的功能主要体现
- 性能的提高:主要以增加缓冲的方法来提高输入输出的效率
- 操作的便捷:处理流提供了一系列便捷的方法来一次输入输出大批量的数据,使用更加灵活方便
- 关闭处理流时只需要关闭外层流即可
对象处理流注意事项和细节
- 读写顺序要一致
- 需要序列化和反序列化的对象需要实现Serializable接口
- 序列化的类中建议添加SerialVersionUID,为了提高版本兼容性
- 序列化对象时,默认将里面所有属性都进行序列化,但除了static和transient修饰的成员
- 序列化对象时,要求里面属性的类型也需要实现Serializable接口
- 序列化具备可继承性,也就是如果某类已经实现了Serializable接口,则它的所有子类也已经默认是实现了序列化
标准输入输出流
- System.int:编译类型为InputStream,运行类型为BufferedInputStream
- System.out:编译类型和运行类型为PrintStream
转换流
- InputStreamReader
- OutputStreamWriter
打印流
- PrintStream
- PrintWriter
网络编程
网络通信的本质是套接字(socket)之间的通信。
TCP编程
基本流程
- 服务端用new ServerSocket(port) 在指定端口监听,等待客户端连接
- 客户端 new Socket(ip, port) 连接指定Ip和端口
- 服务端调用 serverSocket.accept() 获取套接字
- 服务端与客户端分别通过 socket 来获取 OutputStream、InputStream,对流进行读写数据来实现通信
UDP编程
基本流程
- 核心的两个类是DatagramSocket和DatagramPacket
- 建立发送端、接收端
- 发送数据前,建立数据包/数据报,DatagramPacket对象
- 调用DatagramSocket的发送、接收方法
- 关闭DatagramSocket
反射
反射机制
基本概念
- 反射机制允许程序在执行期间借助于反射API取得任何类的内部信息(成员变量,构造器,成员方法等),并能操作对项的属性及方法;反射在设计模式和框架底层都会用到
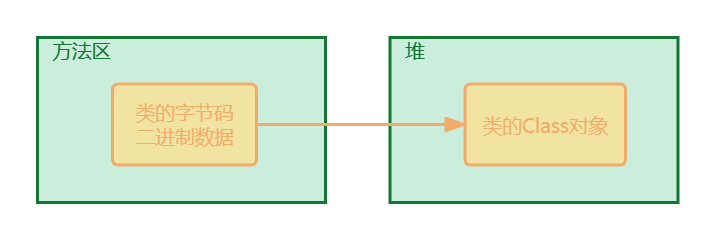
- 加载完类之后,在堆中就产生了一个Class类型的对象(一个类只有一个Class对象),这个对象包含了类的完整结构信息,通过这个对象得到类的结构
可以做什么
- 在运行时判断任意一个对象所属的类
- 在运行时构造任意一个类的对象
- 在运行时得到任意一个类所具有的成员变量和方法
- 在运行是调用任意一个对象的成员变量和方法
- 生成动态代理
反射主要类
- java.lang.Class:代表一个类,Class对象表示某一个加载后在堆中的对象
- java.lang.reflect.Method:代表类的方法
- java.lang.reflect.Field:代表类的成员变量
- java.lang.reflect.Constructor:代表类的构造方法
优缺点
-
优点:可以动态的创建和使用对象,使用灵活,没有反射机制,框架技术就失去底层支撑
-
缺点:使用反射基本是解释执行,对执行速度有影响
-
通过关闭访问检查,提高反射的效率,Method、Field、Constructor对象都有
setAccessible()方法,设置true时表示反射的对象在使用时取消访问检查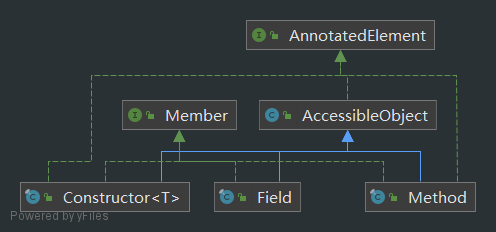
-
Class类
基本概念
- Class也是类,也继承Object类
- Class类对象不是new出来的,而是系统创建的
- 对于某个类的Class类对象,在内存中只有一份,因为类只加载一次
- 每个类的实例都会记得自己是由哪个Class实例所生成
- Class对象存放在堆中
- 类的字节码二进制数据,存放在方法区,也被称为元数据
类的Class对象的获取
- 通过
Class.forName()方法获取 - 通过
类名.class获取 - 通过
对象.getClass()方法获取 - 通过类加载器获取类的Class对象
- 基本数据类型获取Class对象通过
基本数据类型.class获取 - 基本数据类型的包装类通过
包装类.TYPE获取,获取到的Class对象与其基本数据类型的Class对象是同一个
哪些类型有Class对象
- 外部类、成员内部类、静态内部类、局部内部类、匿名内部类
- 接口
- 数组
- 枚举
- 注解
- 基本数据类型
- void
类的加载
反射机制是Java实现动态语言的关键,也就是通过反射实现类动态加载
静态加载
编译时加载相关类,如果没有则报错,依赖性太强
动态加载
运行时加载需要的类,如果运行时不用该类,则不报错,降低了依赖性
加载时机
- 当创建对象时(new)
- 当子类被加载时,父类也会被加载
- 调用类中的静态成员时
- 通过反射
类加载过程
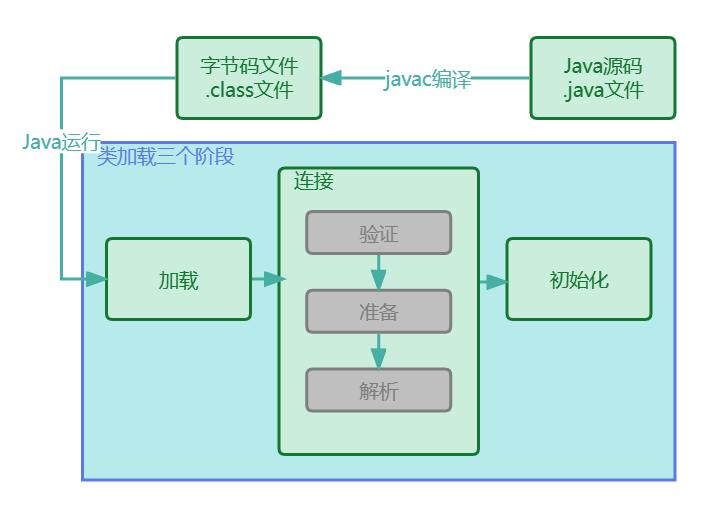
- 加载:将类的class文件(转化为二进制字节流)读入内存,并为之创建一个java.lang.Class对象,此过程由类加载器完成
- 连接:将类的二进制数据合并到JRE中
- 验证:对文件安全性进行校验(文件格式验证、元数据校验、字节码验证和符号引用验证)
- 目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会薇还虚拟机本身
- 可以使用
-Xverify:none参数来关闭大部分的类验证措施,缩短虚拟机类加载的时间
- 准备:对静态变量分配内存并进行默认(对应类型的默认值)初始化,这些变量所使用的内存都将在方法区中进行分配
- 使用
final修饰的静态变量直接初始化为等号后面的值,因为final变量一旦赋值就不可变
- 使用
- 解析:将符号引用(字面)转为直接引用(内存地址)
- 验证:对文件安全性进行校验(文件格式验证、元数据校验、字节码验证和符号引用验证)
- 初始化:JVM负责对类进行初始化,这里主要指静态成员
- 初始化阶段才真正开始执行类中定义的Java程序代码,此阶段是执行<clinit>()方法的过程
- <clinit>()方法是由编译器按语句在源文件中出现的顺序,依次自动收集类中的所有
静态变量的赋值动作和静态代码块中的语句,并进行合并 - 虚拟机会保证一个类的<clinit>()方法在多线程环境中被正确地
加锁、同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类<clinit>()方法,其他线程都需要阻塞等待,直到活动线程执行<clinit>()完毕
类加载后的内存布局:
反射获取类的结构信息
java.lang.Class类
- forName:得到Class对象
- getName:获取全类名
- getSimpleName:获取简单类名
- getFields:获取所有public修饰的属性,包含本类及父类
- getDeclaredFields:获取本类中所有属性
- getMethods:获取所有public修饰的方法,包含本类及父类
- getDeclaredMethods:获取本类中所有方法
- getConstructors:获取本类所有public修饰的构造器
- getDeclaredConstructors:获取本类中所有构造器
- getPackage:获取包信息
- getSuperClass:获取父类Class对象
- getInterfaces:获取接口信息
- getAnnotations:获取注解信息
java.lang.reflect.Field类
- getModifiers:获取修饰符,0(默认修饰符)、1(public)、2(private)、4(protected)、8(static)、16(final),多个修饰符返回修饰符之和
- getType:获取类型的Class对象
- getName:获取属性名
java.lang.reflect.Method类
- getModifiers:获取修饰符,同Field类
- getReturnType:获取返回类型的Class对象
- getName:获取方法名
- getParameterTypes:获取参数类型的Class对象的数组
通过反射创建对象
- 调用类中public修饰的无参构造器,newInstance()
- 调用类中的指定构造器,先通过getConstructors()、getDeclaredConstructors()方法获取指定构造器,再调用newInstance()创建实例
- 当构造器是私有时,可以将构造器设置 setAccessible(true) 进行暴力破解
用过反射调用方法
- 通过getMethods()、getDeclaredMethods()方法获取方法对象
- 私有方法可以设置 setAccessible(true) 进行暴力破解
- 通过 m.invoke(obj, 实参列表) 对方法进行调用
- 若方法是静态方法 invoke方法中的obj参数可以写为null
代理模式与动态代理
代理设计模式的原理
-
使用一个代理将对象包装起来,然后用该代理对象取代原始对象
-
任何对原始对原始对象的调用都要通过代理
-
代理对象决定是否以及何时将方法调用转到原始对象上
-
静态代理:代理类和目标对象的类都是在编译期间确定下来,同时每个代理类只能为一个接口服务,不利于程序的扩展
动态代理的基本概念
- 动态代理是指客户通过代理类来调用其他对象的方法,并且在程序运行时根据需要动态创建目标类的代理对象
- 使用场景:调试、远程方法调用
- 相比于静态代理的优点:抽象类(接口)声明的所有方法都被转移到一个集中的方法中处理,可以更加灵活和统一的处理众多方法
动态代理示例代码
1 | |
Mysql基本知识
本文只是简单记录下一些mysql的知识点
数据类型
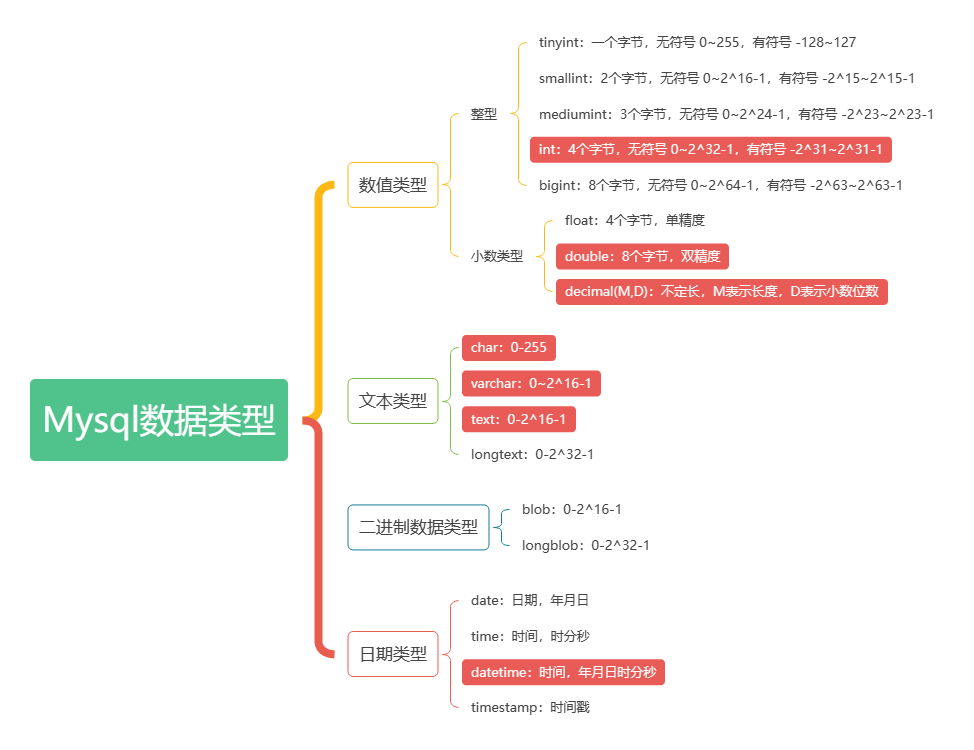
- char是固定长度字符串,最大255
字符,实际占用空间=定义的字符数所占空间 - varchar是可变长度字符串,最大65535
字节,能存放字符数取决于编码,如utf8编码最大21844((65535-3)/3)字符,1-3个字节用于记录大小,实际占用空间=内容所占字节+长度记录所占的1-3个字节 - char(4)、varchar(4)中的4表示字符数(不区分字母汉字),不是字节
查询
-
多表查询:多表查询时至少要有查询表数量-1个条件,避免产生笛卡尔积
1
select * from t1, t2 where t1.tid = t2.id; -
自连接
1
select a.name as name1, b.name as name2 from t1 as a, t1 as b where a.pid = b.id; -
子查询
1
2
3
4select * from t1 where id in (select tid from t2 where name like '%a%');
-- 子查询作为临时表
select t1.* from (select tid, max(num) from t1 group by tid) as tmp, t1
where tmp.tid = t1.tid and tmp.num = t1.num; -
合并查询
1
2
3
4
5
6
7
8
9-- union all 结果数量为多个查询结果数之和,不会去重
select name, age from t1 where name like '%王%'
union all
select name, age from t1 where age > 18;
-- union 查询结果会去重(根据列值都相同进行去重)
select name, age from t1 where name like '%王%'
union
select name, age from t1 where age > 18; -
外连接
-
左外连接:左侧表完全显示(左侧表与右侧表没有关联的数据也显示)
1
select l.name, r.name from l left join r on l.rid = r.id; -
右外连接:右侧表完全显示(右侧表与左侧表没有关联的数据也显示)
1
select l.name, r.name from l right join r on l.rid = r.id;
-
索引
好的索引能大大提高查询速度;索引本身也是占用空间的
索引的原理
字段不加索引时,查询该字段会进行全表扫描,所以会慢
创建索引时(btree、hash),会形成一个索引的数据结构,如b+树或者hash表,然后存储起来,从而提高查询速度
但是对表进行DML(修改、删除、新增)时会对索引进行维护,进而影响速度
索引类型
- 主键索引:primary key
- 唯一索引:unique
- 普通索引:index
- 全文索引:fulltext,适用于MyISAM,一般不使用
索引方法
- B+Tree
- hash
创建索引的情况
- 较频繁的作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的子弹不适合创建索引
- 不会出现在where子句中的字段不该创建索引
事务隔离级别
基本概念
-
定义了事务与事务之间的隔离程度
-
多个连接开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个连接在获取数据时的准确性
-
如果不考虑隔离性,可能会引发如下问题:
- 脏读:当一个事务读取另一个事务尚未提交的改变时,产生脏读
- 不可重复读:同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生不可重复度(说的是变没变化的问题:原来是A,现在却变为了B,则为不可重复读)
- 幻读:同一查询在同一事务中多次进行,由于其他事务所做的插入操作,每次返回不同的结果集,此时发生幻读(说的是存不存在的问题:原来不存在的,现在存在了,则是幻读)
隔离级别
| 隔离级别 | 脏读 | 可不重复读 | 幻读 | 加锁读 |
|---|---|---|---|---|
| 读未提交 Read uncommitted | √ | √ | √ | 不加锁 |
| 读已提交 Read committed | × | √ | √ | 不加锁 |
| 可重复读 Repeatable read | × | × | √ | 不加锁 |
| 可串行化 Serializable | × | × | × | 加锁 |
可重复读一般不会出现幻读,当B事务插入数据并提交后,A事务执行了没有条件的update,这个update会作用在所有的行上(包括B事务插入的数据),此时A事务会产生幻读
事务ACID
- 原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生
- 一致性(Consistency):事务必须使数据库从一个一致性状态变换到另外一个一致性状态
- 隔离性(Isolation):事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要互相隔离
- 持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
表类型与存储引擎
- mysql的表类型由存储引擎决定,主要包括MyISAM、InnoDB、Memory等
- 数据表主要支持六种类型,CSV、Memory、ARCHIVE、MRG_MYISAM、MyISAM、InnoDB
- 以上六种类型可以分为两类
- 事务安全型:InnoDB
- 非事务安全型:其余都是
1 | |
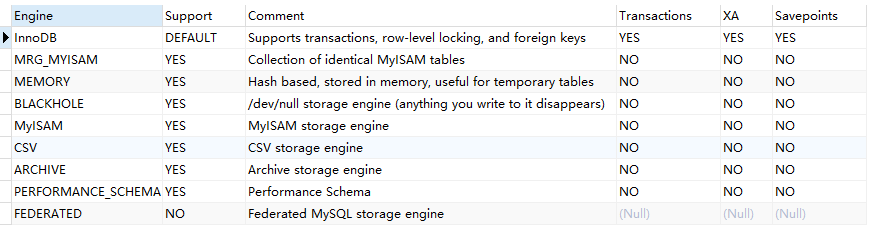
特点
| 特点 | InnoDB | MyISAM | Memory | ARCHIVE |
|---|---|---|---|---|
| 批量插入速度 | 低 | 高 | 高 | 非常高 |
| 事务安全 | 支持 | |||
| 全文索引 | 支持 | |||
| 锁机制 | 行锁 | 表锁 | 表锁 | 行锁 |
| 存储限制 | 64TB | 没有 | 有 | 没有 |
| B树索引 | 支持 | 支持 | 支持 | |
| 哈希索引 | 支持 | 支持 | ||
| 集群索引 | 支持 | |||
| 数据缓存 | 支持 | 支持 | ||
| 索引缓存 | 支持 | 支持 | 支持 | |
| 数据可压缩 | 支持 | 支持 | ||
| 空间使用 | 高 | 低 | N/A | 非常低 |
| 内存使用 | 高 | 低 | 中等 | 低 |
| 支持外键 | 支持 |
JDBC和连接池
JDBC概述
JDBC为不同的数据库提供了统一的接口,为使用者屏蔽了细节问题;使用JDBC可以连接任何提供了JDBC驱动程序的数据库系统,从而完成对数据库的各种操作。
JDBC API
JDBC API是一系列的接口,它统一和规范了应用程序与数据库的连接、执行SQL语句,并得到返回结果等各类操作,相关类和接口在java.sql和javax.sql中
JDBC程序编写步骤
- 注册驱动:加载Driver类
- 获取连接:得到Connection
- 执行增删改查:发送sql给数据库执行
- 释放资源:关闭相关连接
DriverManager
获取连接
Connection接口
创建Statement对象、或PreparedStatement对象
Statement接口
- Statement对象用于执行静态sql语句并返回其生成的结果的对象
- 主要有三类
- Statement:存在sql注入问题
- PreparedStatement:预处理,大大减少编译次数,效率较高;解决sql注入问题
- CallableStatement:可以使用存储过程
- executeUpdate(sql):执行DML语句,返回影响的行数
- executeQuery(sql):执行查询,返回ResultSet对象
- execute(sql):执行任意sql,返回布尔值
PreparedStatement接口
- executeUpdate():执行DML语句,返回影响的行数
- executeQuery():执行查询,返回ResultSet对象
- execute():执行任意sql,返回布尔值
- setXXX(占位符索引,占位符的值):索引从1开始,解决sql注入问题
ResultSet
-
获取到对象时在列名行
-
next():向下移动一行,若没有下一行,返回false
-
previous():向前移动一行
-
getXXX(列的索引或列名):索引从1开始,获取列的值
-
和连接关联,若连接被关闭则无法使用
事务
创建Connection时,默认是自动提交事务的;通过 setAutoCommit(false) 关闭自动提交事务;通过 commit() 和 rollback() 方法手动提交事务和回滚事务
批处理
当需要批量插入或批量更新时,可以采用jdbc批量更新机制,这一机制允许多条语句一次性提交给数据库批量处理,通常情况下比单独提交处理更有效率;若要使用批处理功能需要在jdbc连接中加入 rewriteBatchedStatements=true 参数;通常与 PreparedStatement 一起搭配使用,可以减少编译次数,减少运行次数,效率大大提升。
-
批量包底层是一个ArrayList,按1.5倍扩容
-
addBatch():添加需要批量处理的sql语句或参数到批处理包
-
execteBatch():执行批量处理语句
-
clearBatch():清空批处理包中的语句
连接池
使用传统方式连接数据库,不能控制创建的连接数量,若连接过多,可能会导致内存泄露,mysql服务崩溃
使用数据库连接池技术解决数据库连接问题
基本介绍
- 预先在缓冲池中放入一定数量的连接,当需要建立连接时,只需从缓冲池中取出一个连接,使用完毕后再放回去
- 数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的连接,而不是重新创建一个
- 当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中
- 在JDBC中使用 javax.sql.DataSource 来表示,该接口由第三方提供实现
c3p0
速度相对较慢,稳定性不错
druid
阿里开源的数据库连接池,功能全面,扩展性较好,监控完善
HikariCP
性能十分优异,号称java平台最快的数据库连接池;在并发较高的情况下,性能基本上没有下降
Java8新特性
- Lambda表达式
- 函数式接口(Functional):只有一个方法
- 方法引用与构造器引用
- 强大的Stream API
- Optional类
Lambda表达式
格式说明
- (lambda形参列表) -> lambda体
- -> 被称为lambda操作符或箭头操作符
- 左边的lambda形参列表其实就是接口中的抽放方法的形参列表
- lambda体其实就是重写的抽象方法的方法体
Lambda表达式的使用
- lambda形参列表的参数类型可以省略(类型推断)
- 若lambda形参列表只有一个参数,一对小括号可以省略
- lambda体应该使用一对花括号包裹
- 若lambda体只有一条执行语句,可以省略花括号和return关键字
函数式接口
基本概念
- 只有一个抽象方法的接口,称为函数式接口
- 可以通过Lambda表达式来创建该接口的对象
- 在一个接口上使用 @FunctionalInterface 注解,可以检查它是否是一个函数式接口
- 在 java.util.function 包下定义了Java8的丰富的函数式接口
核心函数式接口
| 函数式接口 | 说明 | 参数类型 | 返回类型 | 用途 |
|---|---|---|---|---|
| Consumer<T> | 消费型接口 | T | void | 对类型T的对象应用操作 |
| Supplier<T> | 供给型接口 | 无 | T | 返回类型为T的对象 |
| Function<T, R> | 函数型接口 | T | R | 对类型T的对象应用操作,并返回结果;结果是R类型的对象 |
| Predicate<T> | 断定型接口 | T | boolean | 确定类型为T的对象是否满足某约束,并返回boolean值 |
方法引用与构造器引用
- 当要传递给lambda体的操作,已经有实现的方法了,可以使用方法引用
- 本质上就是Lambda表达式,而Lambda表达式作为函数式接口的实例,所以方法引用也是函数式接口的实例
- 使用格式:类(或对象)
::方法名- 对象::非静态方法
- 类::静态方法
- 类::非静态方法
Stream API
- 集合讲的是数据(与内存打交道),Stream讲得是计算(与CPU打交道)
- Stream自己不存储元素,数据依旧在集合中
- Stream不会改变源对象,但他可以返回一个持有结果的新Stream
- Stream操作分为三个步骤,创建、中间操作、终止操作
- Stream操作是延迟执行的,这意味着他们会等到需要结果(执行终止操作)的时候才执行
Stream的创建
-
通过集合
1
2
3
4
5List<User> users = selectByOrgId();
// 顺序流
Stream<User> stream = users.stream();
// 并行流
Stream<User> parallelStream = users.parallelStream(); -
通过数组
1
2int arr = new int[]{1, 2, 3};
IntStream stream = Arrays.stream(arr); -
通过Stream.of方法
1
Stream<Integer> stream = Stream.of(1, 2, 3); -
创建无限流
1
2
3
4
5// 无限流之迭代方法,获取前10个偶数
Stream.iterate(2, i -> i + 2).limit(10).forEach(System.out::println);
// 无限流之生成方法,获取10个随机数
Stream.generate(Math::random).limit(10).forEach(System.out::println);
// 上面代码中的 limit(10) 为中间操作;forEach 为终止操作
Stream的中间操作
- 筛选与切片
- filter(Predicate p):接收lambda,从流中排除某些元素
- limit(n):截断流,使其元素不超过给定数量
- skip(n):跳过元素,返回一个扔掉了前n个元素的流,若流中元素不足n个,返回一个空流
- distinct:筛选,同过流中元素的 hashCode() 和 equals() 去除重复元素
- 映射
- map(Function f):接收一个函数作为参数,将元素转换为其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素
- flatMap(Function f):接收一个函数作为参数,将流中的每一个值都换成另一个流,然后把所有流连接成一个流(简单理解为二维数组降为一维数组,降维展开)
- mapToDouble(ToDoubleFunction f)
- mapToInt(ToIntFunction f)
- mapToLong(ToLongFcuntion f)
- 排序
- sorted():自然排序,调用流中元素实现Comparable接口的compareTo方法进行比较
- sorted(Comparator c):定制排序
Stream的终止操作
- 匹配与查找
- forEach(Consumer c):遍历元素
- allMatch(Predicate p):检查是否匹配所有元素
- anyMatch(Predicate p):检查是否至少匹配一个元素
- noneMatch(Predicate p):检查是否没有匹配所有元素
- findFirst():返回第一个元素
- findAny():返回当前流中的任意元素
- count():返回流中元素的总个数
- max(Comparator c):返回流中最大值
- min(Comparator c):返回流中最小值
- 归约
- reduce(T identity, BinaryOperator b):将流中元素反复结合起来,得到一个值,返回T的对象
- reduce(BinaryOperator b):将流中元素反复结合起来,得到一个值,返回Optional<T>对象
- 收集
- collect(Collector c):将流转化为其他形式,接收一个Collector接口的实现,用于给Stream中元素做汇总的方法
- Collectors类提供了很多静态方法,可以方便得创建常见收集器实例
- collect(Collector c):将流转化为其他形式,接收一个Collector接口的实现,用于给Stream中元素做汇总的方法
Optional类
使用Optional类来尽可能的避免空指针问题
常用方法
- Optional.of(T t):创建一个Optional对象,t不能为空
- Optional.empty():创建一个空的Optional对象
- Optional.ofNullable(T t):创建一个Optional对象,t可以为空
- boolean isPresent():判断是否包含对象
- void ifPresent(Consumer c):若有值,就执行Consumer接口实现代码,并且该值会作为参数传递给它
- T get():若包含值,返回该值,否则抛异常
- T orElse(T other):若有值则将其返回,否则返回指定的other对象
- T orElseGet(Supplier<? extends T> s):若有值则将其返回,否则返回由Supplier接口实现提供的对象
- T orElseThrow(Supplier<? extends X> s):若有值则将其返回,否则抛出由Supplier接口实现提供的异常