极客时间《正则表达式入门课》笔记
极客时间《正则表达式入门课》笔记
正则表达式的作用
正则表达式一般有三种作用
- 校验数据的有效性
- 查找符合要求的文本
- 对文本进行切割和替换
元字符
正则表达式的基本单元是元字符。
按照理解可以将元字符分类成以下几类
- 特殊单字符
- 空白符
- 范围
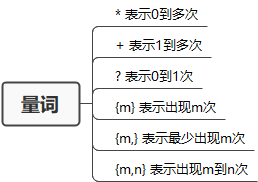
- 量词
- 断言
特殊单字符

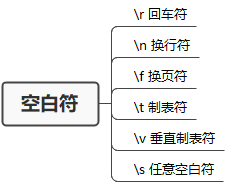
空白符
量词
范围

量词与贪婪
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
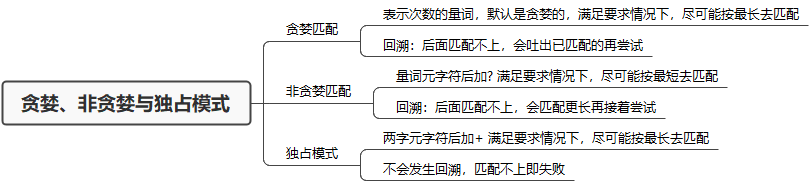
独占模式
不管是贪婪模式,还是非贪婪模式,都需要发生回溯才能完成相应的功能。但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了,因此正则中还有另外一种模式,独占模式,它类似贪婪匹配,也会尽可能多的匹配,但匹配过程不会发生回溯,匹配不上就会返回失败,因此在一些场合下性能会更好。
例.
regex = “xy{1,3}z”
text = “xyyz”
贪婪模式下,y{1,3}会尽可能长的去匹配,及三个y,但字符串最后一个字符为z导致匹配不上,这时就会向前回溯,吐出当前字符 z,接着用正则中的 z 去匹配。

修改表达式为非贪婪模式
regex = “xy{1,3}?z”
非贪婪模式下,y{1,3}?会尽可能短的去匹配,当匹配了一个y后,正则会用z与字符串中的第三个字符y比较,发现不匹配,这时正则就会向前回溯。

独占模式就是在量词后面加上+
修改为独占模式
regex = “xy{1,3}+yz”

TIPS
如果你有一个问题,你想到可以用正则来解决,那么你有两个问题了。
Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.
提醒我们在写正则的时候,一定要思考下回溯问题,避免使用低效的正则,引发线上问题。
分组与引用
分组
在正则中使用()来分组,使用括号分组的表达式会保存子组(如果正则中出现了括号,那么我们就认为,这个子表达式在后续可能会再次被引用,会影响性能),每对括号会分配一个编号。
在括号内使用?:就可以不保存子组(不保存子组可以提高正则的性能),不会被分配编号。
在分组嵌套的情况下判断分组编号可以通过各分组左括号的顺序的判断。

引用
在知道了分组的编号后(number),可以使用\number来对分组进行引用。
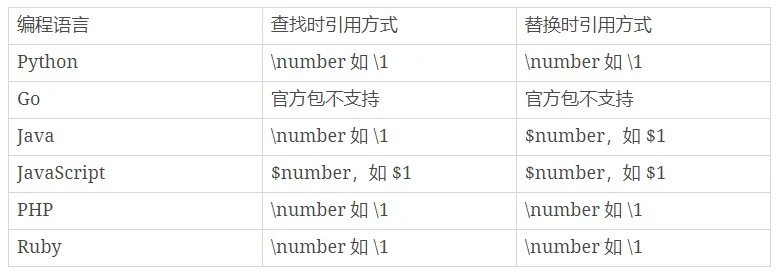
使用分组引用来替换
1 | |
使用分组引用来查找
匹配模式
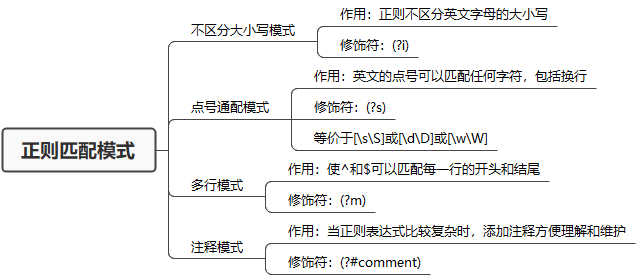
所谓匹配模式,指的是正则中一些改变元字符匹配行为的方式,比如匹配时不区分英文字母大小写。常见的匹配模式有 4 种,分别是不区分大小写模式、点号通配模式、多行模式和注释模式。
将模式修饰符放在正则表达式的前面就表示是此模式。模式修饰符是通过(? 模式标识) 的方式来表示的。
不区分大小写模式(Case-Insensitive)
不区分大小写的模式修饰符是(?i)。
例,不区分大小写匹配dog
(?i)dog
注意,如果模式修饰符在括号内,则作用范围是这个括号内的正则,而不是整个正则。
点号通配模式(Dot All)
点号通配模式的作用是可以让英文的.可以匹配任意字符。
模式修饰符是(?s)。
例
(?s).+
多行匹配模式(Multiline)
通常情况下,^匹配整个字符串的开头,$ 匹配整个字符串的结尾。多行匹配模式改变的就是 ^ 和 $ 的匹配行为。
模式修饰符为(?m)。
例,匹配所有以the开头,以dog结尾的行
(?m)^the|dog$
注释模式(Comment)
用于对正则进行注释说明。
模式修饰符为(?#comment),comment为注释内容。
例
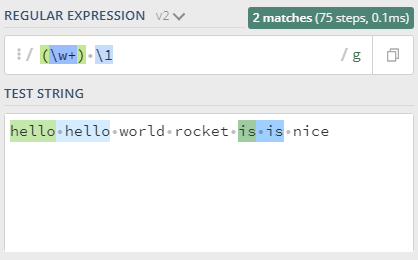
(\w+)(?#word) \1(?#word repeat again)
总结
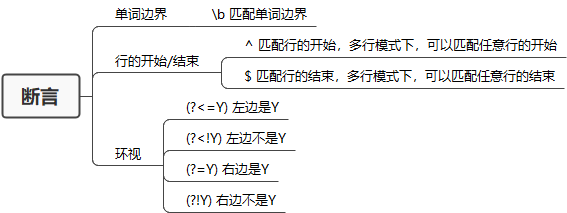
断言
断言的定义为只用于匹配位置,而不是文本内容本身。
常见的断言有三种:单词边界、行的开始或结束以及环视。
单词边界
在正则中使用\b来表示单词的边界
例,匹配句子中的单词tom
tom tomorrow.
正则写法:\btom\b
表示匹配以tom开头,以tom结束的单词
行的开始或结束
在正则中使用^表示文本行的开始,$表示文本行的结束,配合前面讲到的多行模式(?m)可以实现多行匹配。
环视
环视就是要求匹配部分的前面或后面要满足(或不满足)某种规则。
| 正则 | 名称 | 含义 |
|---|---|---|
| (?<=Y) | 肯定逆序环视 | 左边是Y |
| (?<!Y) | 否定逆序环视 | 左边不是Y |
| (?=Y) | 肯定顺序环视 | 右边是Y |
| (?!Y) | 否定顺序环视 | 右边不是Y |
左尖括号代表看左边,没有尖括号是看右边,感叹号是非的意思。
注:环视正则表达式中的括号不会被视为子组。
总结
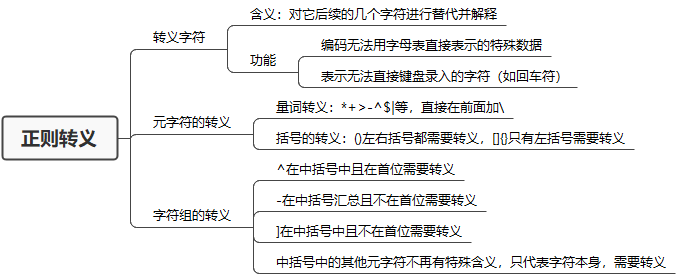
正则转义
正则中使用\来进行转义。
元字符的转义
如果在正则中要查找元字符本身时需要使用转义字符。
量词转义
量词*、+、>、-、^、$、|等,直接在前面加\。
括号的转义
在正则中方括号[]和 花括号 {} 只需转义开括号,但圆括号 () 两个都要转义。
使用函数消除元字符特殊含义
使用过多的转义字符会影响正则表达式的阅读和理解,可以使用编程语言自带的转义函数来实现转义。
| 编程语言 | 转义函数 |
|---|---|
| python | re.escape(text) |
| go | regexp.QuoteMeta(text) |
| java | Pattern.quote(text) |
字符组的转义
字符组就是用方括号[]表示的一些字符,如[a-z]。
字符组中需要转义的有三种情况:
^在方括号中,且在首位-在方括号中,且不再首位]在方括号中,且不再首位
方括号中的其他元字符不再具有特殊含义,仅代表字符本身。
总结
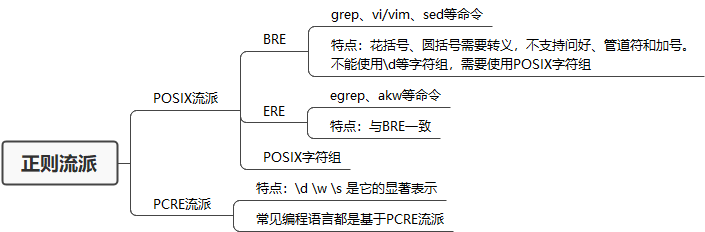
正则表达式流派
由于各种历史原因导致正则表达式有很多种流派,其中POSIX 流派与PCRE 流派是目前正则表达式流派中的两大最主要的流派。
POSIX流派
Unix 系统或类 Unix 系统上的大部分工具,如 grep、sed、awk 等,均遵循该标准。
POSIX 规范定义了正则表达式的两种标准:
- BRE 标准(Basic Regular Expression 基本正则表达式)
- ERE 标准(Extended Regular Expression 扩展正则表达式)
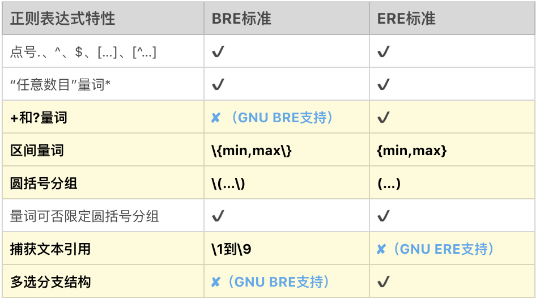
linux下的一些命令默认使用BRE标准,可以使用参数来使用ERE标准或PCRE标准。
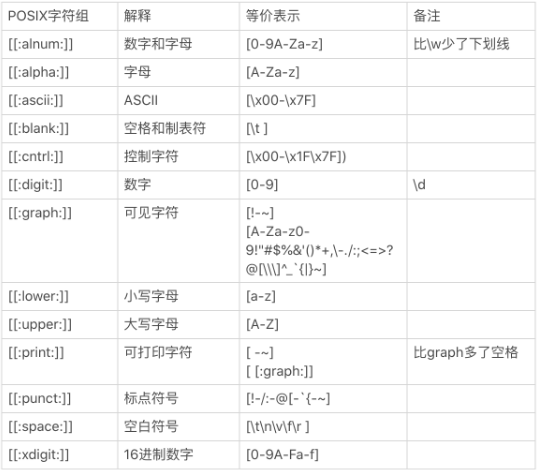
POSIX字符组
与一般的正则表达式不一样的是,POSIX定义了自己的字符组。
PCRE流派
目前绝大部分常用编程语言所采用的正则引擎,基本都属于 PCRE 流派。
但是不同的编程语言还有兼容问题。
- 直接兼容:perl、php、preg、pcre库等perl系
- 间接兼容:java系、python系,JavaScript系、.net系等
总结